
Stop Trying To Make LLMs.txt Happen
Eons ago, MySpace enabled two consenting users to publicly agree if their relationship status was ‘Complicated’ — essentially announcing they were emotionally unavailable and confused as to why.
That pretty much sums up how I feel about llms.txt.

What is LLMs.txt?
It’s a proposed web standard. A single file on your site that’s clean, and can quickly communicate to LLMs what your site (or brand) is, and what service (or products) you offer. It’d offer LLMs something that’s super lightweight (no CSS or JavaScript to stylize it cus it just needs to be readable for bots), and you’d point LLMs where to go for specific things.
In the same way that you go to any site and can check out their /robots.txt file, you would be able to visit a site’s llms.txt file. Picture a nike(dot)com/llms.txt:
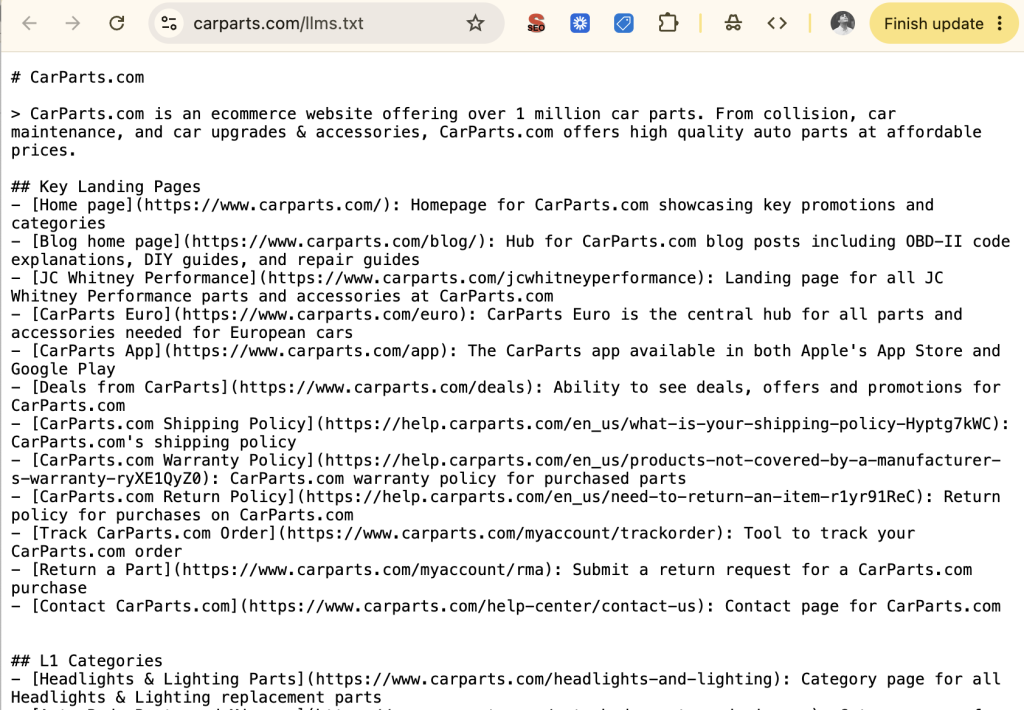
That doesn’t sound bad, but if you think about it for longer than 30 seconds, you’ll realize, “Doesn’t the home page do that? If it doesn’t do that, shouldn’t it?”
It’s like those “elevator pitches,” like if you’re having a hard time communicating what it is that you do — that’s the problem.
Take this Reddit post from good ol’ John Mueller:
Is the site really what they claim it’s about in the llms.txt file? Better check the site itself!
So llms.txt is either correct in the site doing what it claims to do… in which case bots still had to visit the site to verify it;
or llms.txt is incorrect and HOO BOY, that’d lose all credibility with the bot (and me, and presumably, MOST humans).
At which point, you may realize, “llms.txt invented an unnecessary step.”
And yes.
Yes it did.
But okay, if llms.txt is superfluous (at best) and credibility ruining (at worst), then why is it still a topic of conversation?
Three reasons and I’ll address these in descending order of importance:
- Google’s Mixed Signals
- A New Web Standard
- GEO-Bros!
For a meaningless ranking, I’d label these as: 10, 3, 1 — 1 being the least important.
Google’s Giving Mixed Signals About LLMs.txt??
Sort of.
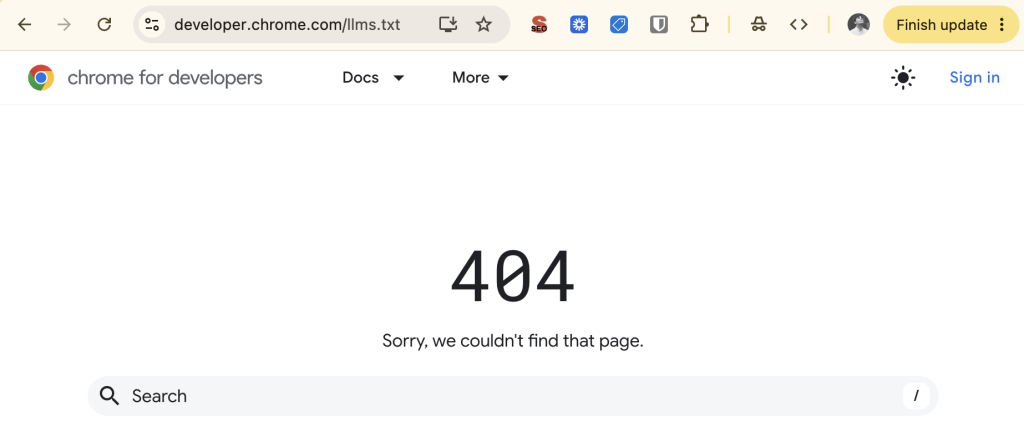
Chrome’s Lighthouse Audit includes a “check” for your site’s llms.txt file (whoops).
Shortly after, Google added an llms.txt file to their developer subdomain… and removed that one too (oops).
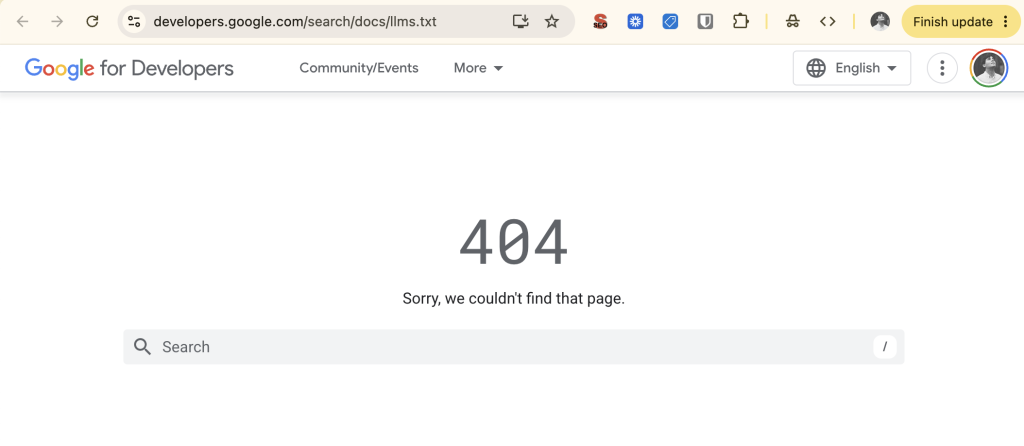
SEOs (like Lily Ray) cut through the noise and requested an explanation from Google’s grandmaster Oogway himself (John Mueller), who said:
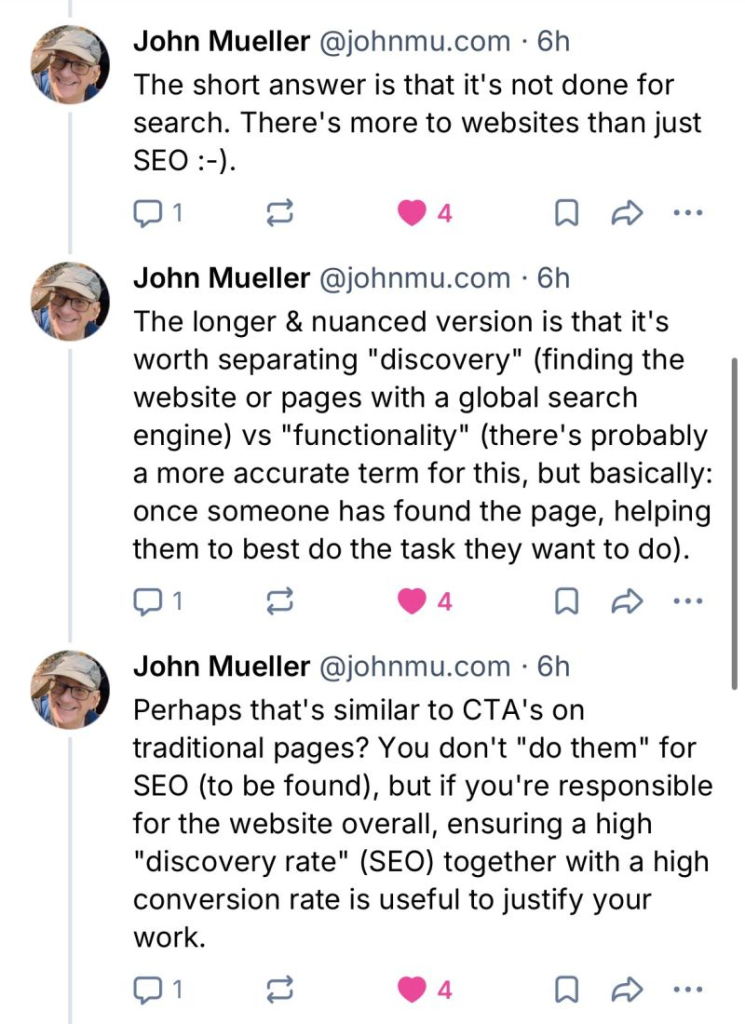

I used to think I was being overly English-major-y reading into this too much, but in writing what follows, I don’t think I am; I think I’m right.
I’m convinced John Mueller purposely keeps his pronouns vague, but I’ll get to that in a minute.
My take on this exchange is threefold:
1. This is a “penalty” waiting to happen.
Something I still think about is when John Mueller stated to stop calling Google penalties “penalties”. Specifically, “We don’t call them penalties because it implies we’re doing something to you, when it’s really just a result of what you’ve done to your site.” i.e. we didn’t penalize you, you did this to yourself.
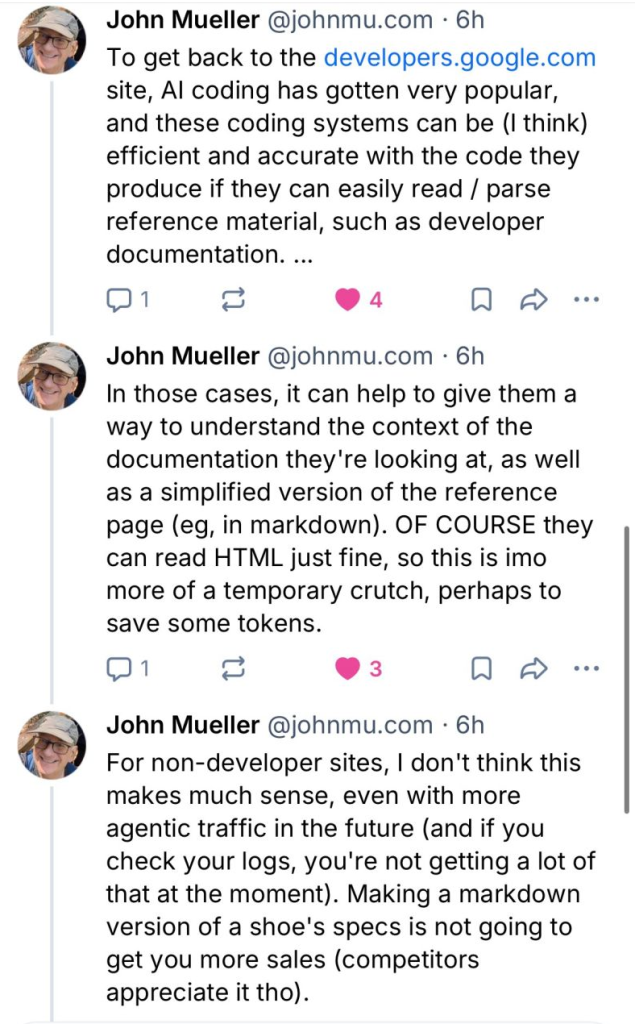
In this tweet exchange, Mueller says, “[LLMs.txt] can give [bots] a way to understand the context of the documentation they’re [(bots)] are looking at… OF COURSE they can (italics for emphasis) read HTML just fine…”
To me, Mueller’s saying, if our “bots” read the llms.txt file and come away with different opinions about what your site is about, then it’s real easy to penalize you. (Again, not that Google penalizes anymore. 🙄)
In other words, it won’t help you rank, but it gives Google an incredibly easy way to catch you lying about your own content context.
2. LLMs.txt may help bots from hallucinating so much.
I think Mueller is being purposely vague with his pronouns. He specifically says, “once someone has found the page, helping them to best do the task they want to do.”
I don’t think he’s talking about humans or users in this, I think he’s talking about the llms/bots. One of the sites I manage has been repeatedly having 5-10% of their “Direct traffic”, single-sessions going to wholly fictitious webpages (see image):
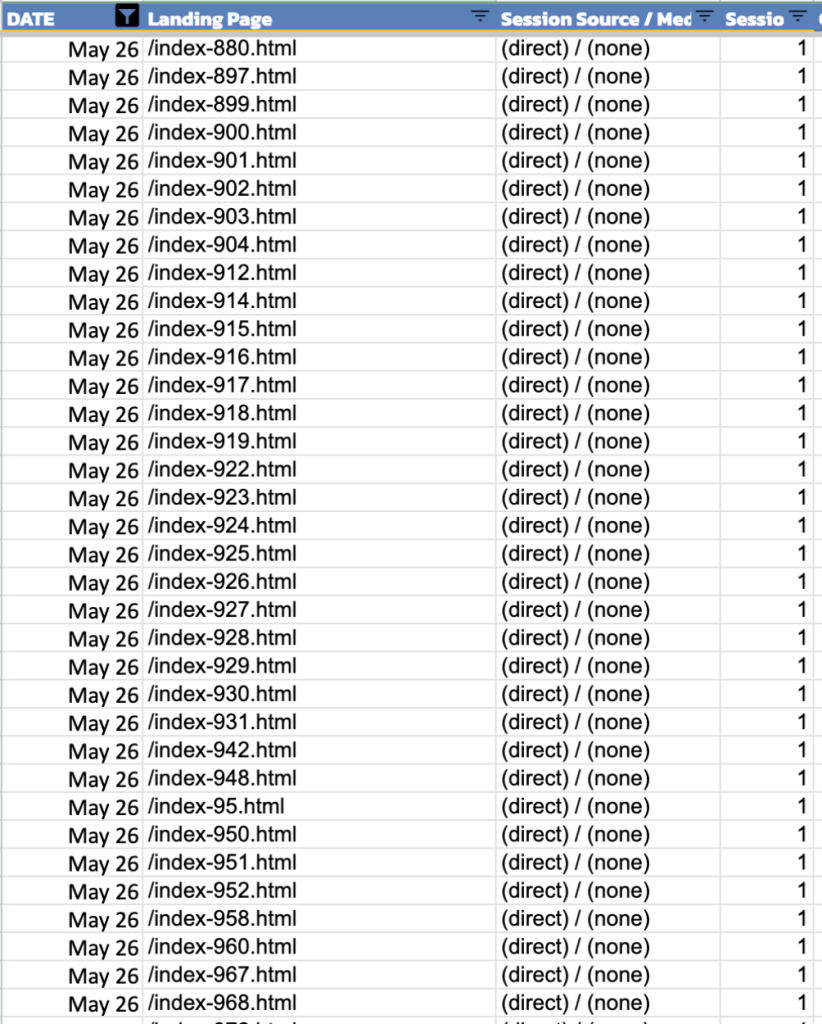
These /index-# pages don’t exist, I don’t link to them from anywhere, they weren’t injected into the site, they’re just appearing and being hit in sequential order going up, and up and up.
Now, yes, this is a little, 1+1 = purple, but given he goes on to talk about CTAs and the “next intended action,” I think this is resource intensive and potentially what he’s alluding to by llms.txt saving tokens.
And if that is the case, then you’d REALLY not want SEOs to know about it or it’d be real easy to game an llms file for rankings and visibility.
I think what Mueller’s implying here is if people use LLMs.txt correctly, it could steer the bots to the internally linked and top-nav pages they should crawl and hallucinate less.
3. Google’s not the only player in search.
The final line from Mueller feels a little bit like “my bosses told me to say this” but also a little bit like “look, we’re not using LLMs.txt but we know Amazon, OpenAI, DuckDuckGo, Bing and others MIGHT.
Without outright giving competitors a nod, it feels — and this is a STREEEEEEEEEETCH, I admit, but — like Google recognizes it’s monopoly could change.
I don’t know if Google was rattled or not when ChatGPT became the leading AI chatter — though given the condition Bard was in on launch, I’m inclined to think they were — but I do think this whole ACP (Agentic Commerce Protocol) with Amazon, Bing, Shopify, Stripe and OpenAI all getting together to build out their own version of a (Google) Merchant Center scared them.
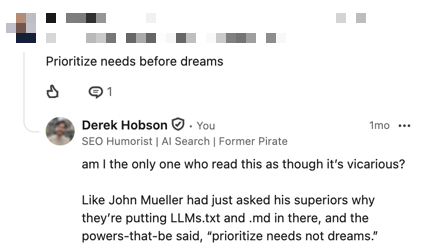
Returning to the point at hand… why is LLMs.txt still a topic of conversation? Reason #2:
It could become a web standard and a “hack” for SEOs with finite dev resources and/or CMS access.
As far as it being a hack, we’ve all been there — finite dev resources and limited CMS access but desperate to make change. The LLMs.txt file could be the solve for that.
That sounds noble enough, but like the meta keywords prior to it, we’re talking about something that’s REMARKABLY low lift.
LLMs.txt is the Cliff’s Notes of your site… but worse.
At least Cliff’s Notes have read the material as well as common analyses and criticisms of the text.
Meanwhile, the LLMs.txt file is a desperate SEO saying, “Look, I know there’s lots of departments with their fingers on the website, but ignore their paws and ONLY look at mine.”
It’s not realistic to be used effectively. It’s a flagrant opportunity to go rogue.
I mean look at this: directory.llmstxt.cloud. This is a link farm!
And it’s a bummer cus LLMs.txt could bypass heavy-code sites, or sites with finite sprints/deploy cycles, and it could limit hallucinations, but it’s just too easy to manipulate.
So what about making it a web standard?
Web standards are essentially the rules broadly agreed upon by most (or the major) players in the field — it’s somewhat democratic in that way. It’s why most sites use: HTML, CSS, XML sitemaps, robots.txt, etc. They’re the defined rules.
For instance, take Monopoly.
The codified rules indicate you collect $200 from passing Go. 👍
Now, some people play Monopoly where anytime you’re meant to pay the bank, you put the money in the middle of the board and if you land on Free Parking, you collect the pot.
☝️That’s not codified into the game.
- Web standards are the equivalent of collecting $200 passing Go.
- LLMs.txt is collecting tax dollars on Free Parking.
Gary Illyes and Martin Splitt did a podcast on this not too long ago. They talked about web standardization and how difficult it is for new web standards to catch on.
That said, they also mention how the last web standard was quite a while ago (this was before LLMs.txt was in the conversation).
What’s fascinating about their discussion is how the standardization eventually spreads like a virus. Not a flash-in-the-pan trend but something that continues to build and grow until eventually, as a majority, webmasters broadly agree that “yes, we can all do this (and benefit from it).”
I believe people are still having the conversation in an effort to keep llms.txt alive and web standardizable.
But, I cannot stress enough, LLMs.txt is not a web standard (yet).
And, at least as of this writing, no LLMs use LLMs.txt files.
3. GEO Bros!
It’s easy to sell.
There’s hundreds (if not thousands) of companies asking what they can do about AI; with AI; appearing in AI.
Hell, even when I chat with people about AI, I have to delineate between AI Overviews, AI Mode, and LLMs (which I bucket under ChatGPT, Gemini, Claude, Perplexity) which can feel overwhelming especially when Google is involved in all 3… and if you tell them about how Google invests in Anthropic which owns Claude. And it gets all the fuzzier when you start talking about Bard’s rebrand to Gemini and VEO to Flow and Opals and Gems and Bananos and deals with Apples…
The point being, we’re all collectively past the hand-wavy, “it’s-just-a-fad” and now locked in. SEOs need to offer AI Search or GEO services if they want to compete.
But then you’ve got GEO bros using llms.txt to manufacture a crisis. They claim if your site isn’t formatted perfectly for a bot’s context window, your brand will face “existential risk.”
It’s an easy sell to panicked clients.
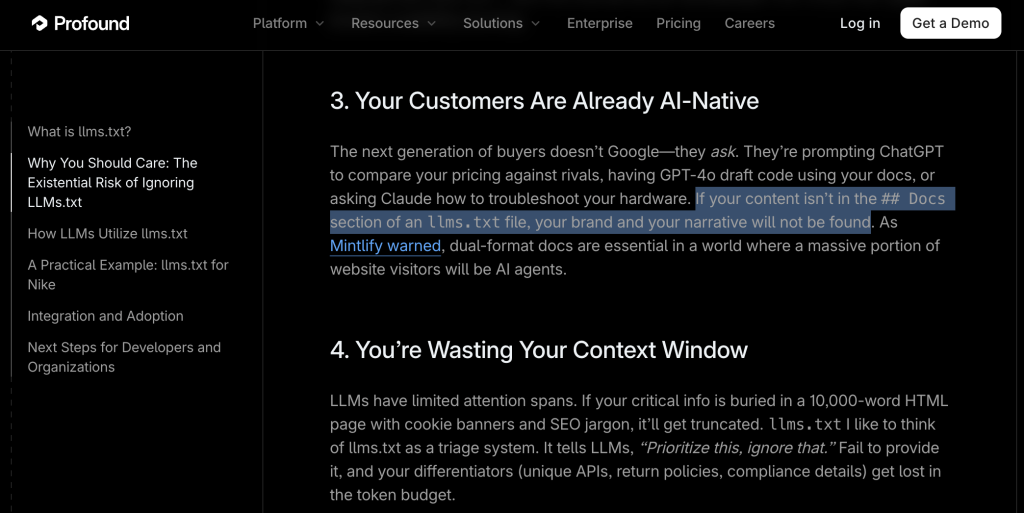
This is a real statement from a new tool (double entendre unintended, but accepted).
Instead of saying, “we’re doing SEO and then some,” you’ve gotta start listing stuff, “we’re doing… X new thing and Y new thing specifically for AI.”
In my opinion, one of the things AI has done is made off-page SEO mandatory, but how I’d package that is “Reddit Strategy” and “YouTube Transcription” or “DPR Syndication.”
And while Paul Shapiro remains tight-lipped, as he said true Generative Engine Optimization isn’t just regurgitating old SEO playbooks under a fancy new name — it’s an entirely unwritten experiment:
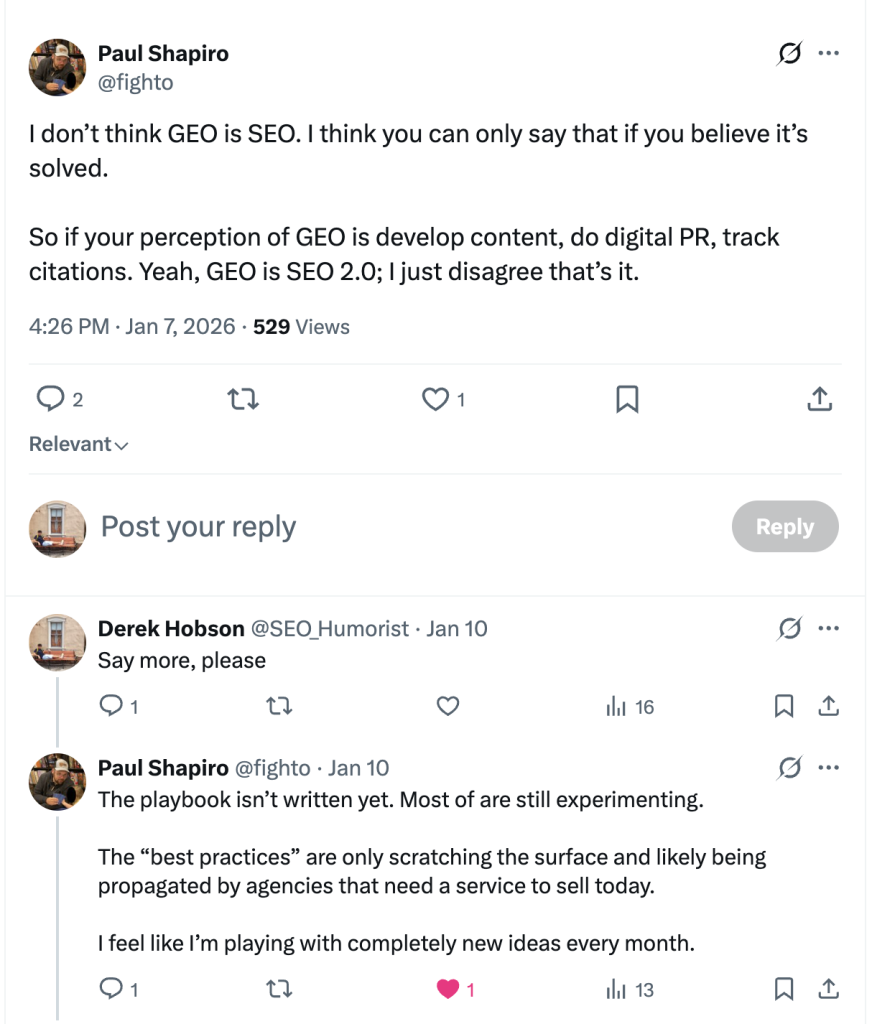
In my opinion, you need seasoned SEOs willing to try something new to understand what GEO could be.
GEO bros just want to slap a new label on an old package and raise the price.
But I digress, I’m still partial to cats.txt.